Беседа одиннадцатая. Машина учится слушать, понимать, говорить
Мир звуков. Звенящие аккорды Скрябина и плеск морской волны, пение птиц и ласковый шелест трав. Исчезни все это, и жизнь померкнет. Среди даров, которыми природа наградила человека, слух - один из драгоценнейших.
Слуховой анализатор человека - это устройство, доведенное природой до высочайшей степени совершенства. Поэтому вполне понятен интерес, проявляемый специалистами по бионике к особенностям строения человеческого уха и соответствующего отдела головного мозга, которые обусловливают удивительную тонкость слуховых восприятий.
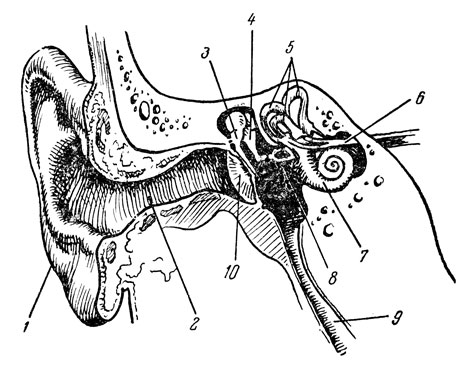
Рис. 1. Ухо человека. 1 - ушная раковина; 2 - слуховой проход; 3 - молоточек; 4 - наковальня; 5 - полукружные каналы; 6 - слуховой нерв; 7 - улитка; 8 - стремечко; 9 - евстахиева труба; 10 - барабанная перепонка (по К. Вилли)
Громкость звуков, которые слышит человек, отнюдь не равнозначна их фактической силе: когда человек стремится понять, что ему говорят тихим шепотом, его слух как бы обостряется. И наоборот, когда у вас над ухом кричат, оно становится менее чутким, чем обычно. Человек способен слышать звуки исчезающе малой интенсивности. Очень сильные звуки не вредят уху, не разрушают его. При силе звука, опасной для слуха, мозг получает сигналы в виде болевых ощущений. Энергии звуковых колебаний, соответствующие интервалу от порога слышимости до болевого порога, отличаются друг от друга примерно в 10 триллионов раз. Ухо очень точно различает частоты чистых тонов. Слуховой анализатор человека шутя справляется и с более сложной задачей: он точно определяет, что не один, а два или несколько чистых тона звучат одновременно. Здесь в органе слуха происходит разложение частот. В определенных случаях - при восприятии музыки и речи - слух воспринимает не отдельные чистые тона, а их определенные комбинации. Например, музыкальная нота - это сумма многих чистых тонов, дающая ощущение определенной высоты (как и чистый тон), но, сверх того, еще и ощущение тембра - окраски звука, зависящей от того, какие чистые тона, кроме основного, присутствуют в данной ноте.
Слуховое восприятие - очень сложный, очень тонкий процесс. Столь же сложна современная теория механизма слуха, и поэтому мы ограничимся лишь выяснением устройства и основных принципов функционирования уха.
Ухо человека изображено в разрезе на рис. 1. Оно состоит из трех частей- наружного, среднего и внутреннего уха.
Наружное ухо в свою очередь состоит из двух частей - покрытого кожей хрящевого выроста, или ушной раковины, и наружного слухового прохода, ведущего от раковины к среднему уху. В месте соединения слухового прохода и среднего уха расположена тонкая соединительно-тканая мембрана - барабанная перепонка, вибрирующая под действием звуковых волн.
Среднее ухо - это небольшая камера, содержащая три крошечные, последовательно соединенные косточки: молоточек, наковальню и стремечко (названные так за свою форму), которые передают звуковые волны через полость среднего уха. Молоточек соприкасается с барабанной перепонкой, а стремечко - с перепонкой, закрывающей отверстие, ведущее во внутреннее ухо и называемое овальным окном. Среднее ухо соединяется с глоткой узкой евстахиевой трубой, служащей для уравнивания давления по обе, стороны барабанной перепонки.
Внутреннее ухо состоит из сложной системы сообщающихся между собой каналов и полостей, которую очень удачно называют лабиринтом. Часть лабиринта, имеющая отношение к слуху, представляет собой спирально закрученную трубку, образующую два с половиной витка и называемую улиткой за сходство с раковиной этого животного.
Звуковые колебания попадают в ушную раковину, проходят наружный слуховой проход и заставляют вибрировать барабанную перепонку. Колебания барабанной перепонки передаются системе слуховых косточек. Последняя косточка системы - стремечко - связана с мембраной овального окна и передает через нее колебания в жидкость внутреннего уха. Жидкость (она, как известно, несжимаема) может колебаться благодаря тому, что мембрана второго круглого окна выгибается в направлении среднего уха. Колебания жидкости вызывают деформацию чувствительных ячеек, которыми выстланы стенки улитки, в результате чего происходит раздражение окончаний волокон слухового нерва. Слуховой нерв передает сигналы раздражения коре головного мозга, где осуществляется окончательный анализ звуков. Ухо почти не утомляется. Несмотря на непрерывные шумовые воздействия, острота слуха сохраняется, и утомление уха исчезает через несколько минут. Когда на одно ухо некоторое время воздействует сильный шум, другое тоже утомляется - утрачивается острота слуха; отсюда следует, что утомление (как и следовало ожидать) частично локализуется не в самом ухе, а в головном мозге.
Поистине природа великолепно одарила человека от щедрот своих. Вероятно, нельзя представить себе более совершенного прибора, чем ухо человека. Полученный от природы в подарок слух дает нам широчайшие возможности звукового общения, обеспечивает, так сказать, существование акустического канала связи с окружающим нас внешним миром. Поэтому потеря или притупление слуха - большое несчастье, которое зачастую становится величайшей трагедией.
Вот несколько строк из писем Бетховена друзьям.
Бетховен Карлу Аменде, 1 июня 1801 г.:
"...Твой Бетховен живет очень несчастливо. Знай, что благороднейшая часть моего существа, мой слух, очень ослабел... Смогу ли излечиться - вопрос будущего... Надеюсь, хоть и сомневаюсь - ведь эти болезни принадлежат к числу неизлечимых..."
Бетховен Вегелеру, 16 ноября 1801 г.:
"День и ночь у меня беспрерывный шум и гудение в ушах. Могу сказать, что жизнь моя жалка: уже два года я избегаю всякого общества. Иногда я еле слышу говорящею тихо, правда, я различаю звуки, но не слова; и все же, когда кричат, это для меня невыносимо... Я часто проклинал свое существование... Терпение! Какое жалкое прибежище, но только оно и остается мне".
О глухоте Бетховена очень много писали медики и музыковеды. Медики, профессионально исследовавшие течение болезни, по характерным ее признакам установили, что Бетховен страдал отосклерозом.
Причина потери слуха при отосклерозе состоит в том, что вокруг стремечка, крохотного последнего звена в цепочке слуховых косточек, разрастается костная ткань, сковывающая его основание. Человек слышит до тех пор, пока звуковая волна выбывает колебания слуховых косточек. Как только стремечко становится неподвижным, слух угасает. Заболевание отосклерозом возникает обычно в период полового созревания или в ближайшие годы после него и носит хронический характер. Практически здоровый человек в расцвете творческих сил без всякой видимой причины теряет слух. Существенное значение в причинах возникновения этого заболевания придают наследственно-конституциональным факторам, звуковой травме, нарушению кровообращения, расстройствам функций эндокринной системы.
До недавнего времени лечение больных отосклерозом лекарственными и физиотерапевтическими средствами оставалось малоэффективным. Дело в том, что все они были направлены главным образом на ослабление одного из тяжелых проявлений отосклероза - ощущения шума в ушах. Основной же симптом заболевания - тугоухость - этими методами устранить не удавалось. На помощь пришла хирургия. И если бы Бетховен жил на полтораста лет позже, советские врачи - отоларингологи - излечили бы великого композитора от тяжелого недуга. С 1963 г. лауреаты Ленинской премии А. И. Коломийченко, В. Ф. Никитина, Н. А. Преображенский, С. Н. Хечинашвили и К. Л. Хилов в разных городах Советского Союза провели сотни операций по поводу отосклероза. Сотням людей, страдавших тем же недугом, что и Бетховен, возвращен слух.
Но отосклероз, с которым так успешно борются советские врачи, не самое тяжкое расстройство слуха. Известно ведь, что и сам Бетховен мог "слышать", например, игру на рояле, упираясь подбородком в ручку трости, другой конец которой прикасался к инструменту. Нервные окончания, воспринимающие звуковые раздражения, функционировали нормально, и поэтому механические колебания, проходя через кости черепа, воздействовали на жидкость внутреннего уха - композитор "слышал".
А как помочь людям с так называемым невритом, развивающимся вследствие нарушения нормальной деятельности самих нервных окончаний, воспринимающих звуковые раздражения? Частичное ослабление слуха можно в известной степени компенсировать, применив обычный аппарат для тугоухих. А если все окончания не функционируют, если связь уха с мозгом нарушена полностью и человек не слышит ни с аппаратом, ни без него?
Недавно в США произошел случай, указавший врачам путь облегчения этого заболевания. Два человека жаловались всем по очереди невропатологам своего города на странный недуг. Время от времени оба слышали голоса людей, которые рекомендовали им купить то холодильник, то мыло, то последнюю модель электробритвы "Ротошейв". В интервалах между уговорами звучала музыка, которая в других обстоятельствах могла бы нравиться, -дело в том, что "голоса" были слышны тогда, когда к испуганным людям никто не обращался, а музыка - когда никто из окружающих ее не слышал.
Врачи были в недоумении - никаких психических расстройств у пациентов не обнаружилось. А между тем они продолжали утверждать, что слышат голоса.
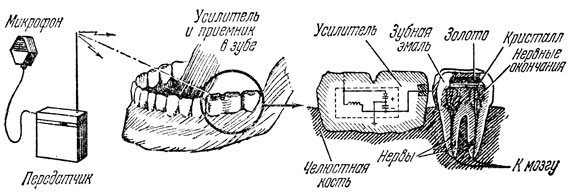
Рис. 2. Схема 'радиозуба'
Наконец, нейрофизиолог доктор Пухарик обратил внимание на то, что оба больных недавно лечили зубы у одного и того же зубного врача по фамилии Лоуренс. Обратились к нему, и стоматолог сказал, что он запломбировал обоим зубы цементом особого состава: в нем была незначительная примесь карборунда.
Постепенно все объяснилось. Кристаллы карборунда - типичного полупроводника - детектировали сигналы местной коротковолновой станции, передававшей торговую рекламу, на которую волей случая оказались "настроенными" зубы, запломбированные цементом с полупроводящей примесью. Низкочастотные колебания воспринимались живым нервом зуба и передавались в мозг.
Так был найден способ использования нервных окончаний зубов (об их связи со слуховыми центрами мозга было давно известно) для восстановления слуха у больных невритом. Лоуренс и Пухарик обратились за помощью к радиоинженерам. Совместными усилиями был создан "радиозуб" - система, с помощью которой сегодня слышат уже несколько человек (рис. 2).
Миниатюрный микрофон, который можно носить на руке, как часы, связан с таким же миниатюрным передатчиком, преобразующим звуки в радиосигналы. Последние улавливает приемник, вмонтированный в зуб. Ничего удивительного в этом нет, если учесть, что приемник представляет собой тонкий слой полупроводникового сплава, наложенного на свободные нервные окончания в зубе. Этот полупроводниковый сплав образует пьезоэлектрический элемент. Сверху он покрыт слоем золота или серебра, который служит антенной.
Сигнал радиопередатчика, принятый такой антенной, попадает в пьезоэлемент. В нем возникают колебания, которые, возбуждая свободные нервные окончания в зубе, передаются в виде нервных импульсов в слуховые центры мозга. И человек, который до сих пор жил в мире без звуков, начинает слышать.
Совсем иначе подошли к проблеме моделирования слуха израильские ученые. Они работают над созданием "телефона" совершенно нового типа, который должен дать возможность глухонемым общаться друг с другом.
Система состоит из передатчика, снабженного клавиатурой с пятью клавишами, манипулируя которыми можно получать различные частоты, и приемника с диафрагмой, позволяющей воспринимать вибрации концами пальцев. В настоящее время задача состоит в том, чтобы разработать рациональный метод кодирования колебаний простой и сложной формы. Код, построенный всего на трех частотах, позволяет создать словарь из 5000 слов.
Пока ведутся психологические исследования: вырабатывается скоростной метод чтения колебаний, определяется время, которое потребуется на обучение коду, и т. д. Кроме того, израильские ученые считают, что связь с космонавтами может быть осуществлена при помощи этого "телефона" с большей четкостью, так как часто случается, что при передаче человеческий голос сильно искажается.
В радиозубе американских ученых электромагнитные колебания превращаются пьезоэлектрическим преобразователем в механические - размеры самого пьезоэлектрического преобразователя определяются амплитудой несущей радиочастоты, промодулированной звуковым сигналом. "Вибрирующий" пьезоэлемент по-разному давит на нервные окончания в зубе, связанные со слуховыми центрами мозга, - возникает слуховое ощущение. А может ли ухо непосредственно воспринимать электромагнитные колебания?
Проделайте такой опыт. Возьмите крышку от алюминиевой кастрюли, присоедините к ее ручке провод и вставьте его в одно из гнезд радиотрансляционной розетки. Приложите крышку к уху и пальцем свободной руки прикоснитесь к другому гнезду розетки. Вы услышите передачу.
В чем же здесь дело?
Ухо, а вернее, барабанная перепонка, с одной стороны, и крышка от кастрюли - с другой, представляют собой две обкладки конденсатора, на который по руке и проводу подается переменное напряжение звуковой частоты. Происходящие при этом явления описаны в разделе "Электричество" школьного курса физики. При увеличении напряжения на обкладках конденсатора увеличивается усилие, стремящееся их сблизить, - барабанная перепонка выгибается в сторону крышки. Когда напряжение уменьшается, перепонка стремится вернуться в первоначальное положение. Таким образом, сравнительно просто создать условия, при которых человек может "слышать" изменения напряжения.
К счастью для человека, из всех видов колебаний, распространяющихся в воздухе, человек воспринимает только свет и звук. Если бы человек ощущал электромагнитные волны любой частоты, то мир, в котором он живет, стал бы для него еще более беспокойным. Однако именно в таком мрачном мире начала жить с 1960 г. домашняя хозяйка из Санта-Барбара. Перебравшись в свой новый дом, госпожа Г. (она предпочла, чтобы ее фамилия осталась неизвестной) начала жаловаться врачам на то, что ее преследует во всех комнатах шум, который никто, кроме нее, не слышит. Доктора, приняв это за галлюцинацию, стали лечить госпожу Г. от обычного психоза, но ей ничего не помогало. По виду вполне здоровая, психически уравновешенная, рассудительная женщина начала было и впрямь сомневаться в своем психическом здоровье. О "болезни" госпожи Г. узнал Кларенс Уиски, научный сотрудник Калифорнийского университета. Специалист по контрольно-измерительной аппаратуре, Уиски решил провести исследования загадочного явления. Отправившись в "наполненную странными звуками" обитель госпожи Г., ученый с помощью чувствительных приборов быстро обнаружил, что в новом доме возникают электромагнитные поля, порождаемые, по-видимому, некоторыми особенностями в конструктивном оформлении электрической, водопроводной, газовой, отопительной, телефонной и радиосети. Не говоря никому о своей догадке, Уиски записал эти обычно неслышимые сигналы на магнитную пленку и затем "проиграл" ее госпоже Г. "И вы хотите сказать, что ничего не слышите?" - удивленно воскликнула она. Уиски действительно ничего не слышал, но это не убедило его в сверхъестественных способностях госпожи Г. Чтобы окончательно разобраться в мучивших его сомнениях, ученый сконструировал устройство, воспроизводившее в общих чертах те же электромагнитные явления, которые наблюдались в доме госпожи Г., и позаботился о том, чтобы всю аппаратуру можно было включать совершенно незаметно. Как только аппаратура начинала работать, госпожа Г. тотчас же начинала жаловаться на слышимые ею шумы. Она также жаловалась на то, что временами слышит сигналы азбуки Морзе высокого тона. Оказалось, что эти сигналы посылала расположенная поблизости радиостанция.
О результатах своих исследований Уиски недавно доложил на конференции специалистов по биологической и медицинской аппаратуре в Лос-Анжелосе. Но сообщение о том, что жительница штата Калифорния способна "слышать" электромагнитные излучения, было принято недоверчиво. Однако на этой же конференции выступил другой ее участник - доктор Аллан Фрей, психолог, который специально изучал влияние электромагнитных полей на психофизиологическое состояние человека.
"Действительно, - подтвердил он, - эксперименты показали, что при воздействии сверхвысокочастотными колебаниями в диапазоне от 200 до нескольких тысяч мегагерц некоторые нормальные и глухие люди слышат звуки. В зависимости от длительности импульсов и частоты их повторения сверхвысокочастотные сигналы воспринимались испытуемыми как жужжание, писк, шипение или стук. В проведенных экспериментах импульсы СВЧ не несли никакой информации. Что же касается механизма восприятия, то я его объяснить не могу".
Зарубежные комментаторы объясняют чрезмерную скромность доктора Фрея тем, что он, в отличие от Уиски, работает по заданию военно-морского ведомства США. Имеются данные, что в настоящее время продолжаются работы по изучению обнаруженного феномена с целью его использования в дальнейшем для передачи информации.
Совершенно очевидно, что в рассмотренном случае в организме людей происходят явления, значительно отличающиеся от тех, которые обеспечивают нормальное звуковое восприятие: ведь сверхвысокочастотное излучение "слышат" некоторые глухие! Здесь уместно напомнить, что звуковой анализатор человека с нормальным слухом в нормальных условиях воспринимает только колебания воздуха - сжатия и разрежения продольной воздушной волны, распространяющейся от звучащего предмета, причем он воспринимает их только в том случае, если частота этих колебаний не превышает 20 000 гц. Природа, совершенствовавшая длительное время человеческий слух, видимо, решила, что слышать более высокие частоты нам ни к чему. А вот слуховой аппарат сов природа наделила способностью воспринимать ультразвуки, издаваемые грызунами. Максимальная частота, которую еще слышат совы, примерно равна 30 кгц. Пользуясь своим слуховым аппаратом, даже слепые совы великолепно ориентируются в пространстве. Их ушная раковина - акустически совершенный рупор - усиливает попадающий на нее звук перед тем, как сфокусировать его на барабанную перепонку.
И тем не менее существуют животные, у которых ушной раковины нет совсем, да и сам орган слуха уж очень не похож на человеческий.
"Уши" насекомых, например, расположены в очень неподходящих для этого местах (с точки зрения человека). Знаете, где уши у паука? Настоящих ушей у него, правда, нет, но он все же может слышать. В дополнение к восьми глазам у пауков есть еще высокочувствительные органы слуха на лапках (рис. 3). Углубление в хитиновом скелете заменяет ему нашу ушную раковину. Слуховой орган, расположенный около ножного сустава, открывается и закрывается в ответ на звуки и вибрацию.
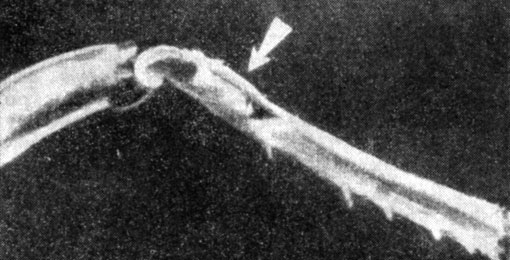
Рис. 3. Ухо паука (показано стрелкой)
Несмотря на кажущуюся простоту, органы слуха насекомых способны воспринимать звуки в чрезвычайно широком диапазоне частот. В ухе ночной бабочки, например, имеется всего три нервных волокна, но оно обнаруживает ультразвуки, издаваемые летучей мышью. Слуховой орган моли воспринимает частоты от 10 до 100 кгц и позволяет обнаруживать приближение летучих мышей на расстоянии до 30 м. "Ухо" моли настолько совершенно и настолько чувствительно, что его использовали для приема сигналов, посылаемых летучими мышами. Для этой цели к нервным волокнам, идущим от слухового органа моли, присоединяли миниатюрные электроды; электрические сигналы милли-секундной длительности, снимаемые со "слухового выхода", записывали на магнитную ленту и затем соответствующим образом обрабатывали для выяснения количества информации, получаемой молью о движении летучей мыши. Работы, проведенные Центром исследований и разработок ВВС США в Кембридже, показали, что два элемента, образующие слуховой орган моли, различаются по чувствительности на 20 - 25 дб.
Немало споров вызвал вопрос о слухе земноводных. Некоторые ученые даже утверждали, что они глухи и не способны воспринимать звуки, которые сами производят. В действительности же последние исследования по нейрофизиологии доказали, что земноводные слышат, но их слух нельзя сравнивать ни со слухом рыб, ни со слухом наземных млекопитающих. Возможно, что некоторое количество вибраций передается не прямо в наружное ухо, а доходит до внутреннего уха кружным путем, через все тело. Некоторые жабы лучше воспринимают звук, когда их слуховые органы наполовину погружены в воду. Прерывистые звуки они слышат лучше, чем непрерывные. Впрочем, разные виды земноводных слышат по-разному, так что какие бы то ни было обобщения здесь затруднительны. Однако несомненно, что обстоятельное изучение органов слуха животных и прежде всего слухового аппарата человека будет способствовать созданию электронных систем, обладающих принципиально новыми свойствами.
Уже одно достижение такой чувствительности у приборов, улавливающих звук, какой характеризуется человеческое ухо, безусловно, имело бы огромное значение для разработки целой гаммы важнейших научно-технических приборов и устройств. Ведь энергетический порог чувствительности нашего уха в 10 раз выше, чем у глаза! Об исключительно высокой чувствительности слухового анализатора человека можно судить по следующим данным. Люди с острым слухом воспринимают звук при звуковом давлении в слуховом проходе, примерно равном 0,0001 дин/см2, что соответствует перемещению элементов улитки уха на величину порядка 10-11 см. Это в 1000 раз меньше диаметра атома водорода! Разрешающая способность человеческого уха также весьма велика. Достаточно сказать, что люди с хорошо развитым слухом могут отличить звук частотой 1000 гц от звука частотой 1001 гц. Отсюда следует, что чувствительность уха человека близка к абсолютной границе различения. Добиться подобной чувствительности технических приборов и систем было бы весьма полезным.
В последнее время в ряде стран получили широкий размах исследования так называемого квазислухового опознавания, имеющие целью создание устройств, моделирующих слуховой аппарат. Исследования органов слуха проводятся главным образом в следующих направлениях:
механизм обработки акустической информации;
акустические сервомеханизмы;
конструктивные особенности органов слуха.
Кроме того, проводится математическое моделирование органов слуха. Некоторые устройства, воспроизводящие функции органов слуха, уже созданы и испытаны. Так, в Лейденском университете в связи с исследованием механизма восприятия звуков человеком разработана электронная модель уха (в виде системы фильтров), воспроизводящая частотные характеристики уха. Моделирование позволило уточнить механизм слуха и, в частности, объяснить такие явления, как восприятие тембра и звуков в их динамике. Одна зарубежная фирма создала электронную модель уха, обеспечивающую, подобно человеческому уху, различение слабых сигналов на фоне шумов за счет корреляционного процесса. Другая разработала модель внутреннего уха, где используются аналоги нейронов - нейромимы.
Интересная разработка выполнена сотрудниками Ленинградского электротехнического института связи имени проф. Бонч-Бруевича. Они создали систему, получившую название "электронное ухо". Электронный прибор определяет, насколько хорошо звучат музыкальные инструменты. Для оценки качества звучания гитары устройству требуется меньше минуты, тогда как весьма компетентный экспертный совет затрачивает на это несколько часов. "Электронное ухо", как опытный педагог-музыкант, выводит инструменту "отметку" по пятибалльной системе.
Уже первый опытный экземпляр "электронного уха" позволил организовать своеобразный "конкурс ушей". Гитарист за занавесом по нескольку раз исполнял специально составленную программу. "Электронное ухо" работало параллельно с советом экспертов. Эксперты-музыканты ставили оценки, на основе которых каждому инструменту был выведен средний балл. Когда их сравнили с оценками прибора (эксперты до этого ничего не знали об оценках, поставленных "электронным ухом" тому или иному инструменту), получилось полное соответствие.
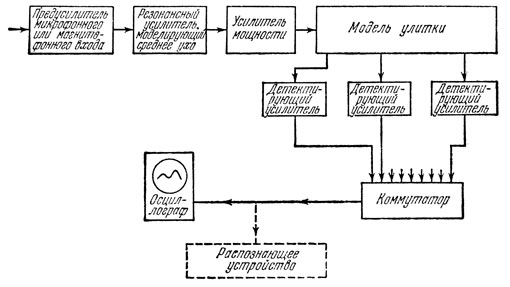
Рис. 4. Блок-схема аналоговой модели уха (по В. Колдуэллу, Э. Глессеру, Дж. Стюарту)
Ряд удачных моделей уха создан фирмами и учебными заведениями США. Примером может служить аналоговая модель уха, разработанная американскими учеными В. Колдуэллом, Э. Глессером, Дж. Стюартом. Модель предназначена для анализа зависимости интенсивности звучания разных частот в произносимых человеком звуках от времени с целью выявления признаков, по которым человек опознает звуки, фонемы и слова, произнесенные разными людьми. Блок-схема устройства показана рис. 4.
Из рисунка ясно, что блоки системы точно воспроизводят функции, которые выполняют разные части человеческого уха. Так, входной предусилитель модели играет роль ушной раковины, которая усиливает звук, передаваемый ею на барабанную перепонку. Второй каскад выполняет функцию среднего уха.
Почему человек не слышит звуков, частота которых превосходит 20 кгц? Потому что колебания такой частоты очень плохо воспроизводятся барабанной перепонкой и слуховыми косточками. Дело в том, что эти части уха слишком тяжелы и не успевают колебаться вслед за слишком "быстрыми" ультразвуковыми колебаниями. Иначе говоря, амплитуда ультразвуковых колебаний "на выходе" из среднего уха равна нулю. Но те же слуховые косточки плохо передают низкие частоты в несколько герц - колебания получаются слишком медленными и очень слабыми. Таким образом, среднее ухо работает так же, как обычный узкополосный (резонансный) усилитель, более или менее одинаково усиливающий колебания в диапазоне от нескольких герц до 20 кгц (второй каскад блок-схемы). "Усилителем мощности", рассеиваемой в улитке уха (третий каскад блок-схемы), служит вся гидравлическая система улитки, в которой создается давление на чувствительные элементы (оно должно быть достаточным для четкого восприятия звука). Модель улитки представляет собой линию с распределенными R, L, С, к разным точкам которой подключены "чувствительные элементы" - усилители. В разных точках аналога улитки (линии с распределенными параметрами), к которым подключены усилители, звуковой сигнал звучит по-разному. Исследователей интересовали только величины его амплитуд в разных точках, а не частоты; поэтому усилители (они же чувствительные элементы) еще детектировали усиливаемый сигнал, так что на экране осциллографа изображалась по очереди форма огибающих сигнала, соответствовавшая разным частотам. Очередность подачи на вход осциллографа сигналов с разных точек "улитки" обеспечивал коммутатор. Аналогичного устройства в ухе нет, но предполагается, что сигналы возбуждения, передаваемые нервными волокнами, претерпевают в мозге весьма сложную коммутацию: "оттуда - сюда, отсюда - туда".
Результаты исследования "звуковых узоров", воспроизводимых моделью на экране осциллографа, получились весьма неожиданными. Оказалось, что "узоры", соответствующие одному и тому же звуку или фонеме, произносимым одним человеком, зачастую совершенно непохожи друг на друга. Например, при 100 повторениях буквы I (ай) одним и тем же лицом получалось 30 различных картин. Так что мозг и слуховой аппарат человека производят поистине титаническую работу, отыскивая признаки, по которым можно определить (и действительно определяют!), что слово "бионика", произнесенное гнусавым басом и свистящей фистулой, - одно и то же слово.
Способность человеческого мозга разбираться с помощью слухового аппарата в джунглях звуков, выделять из кажущегося хаоса значимые формы является одним из его самых чудесных свойств. В раскрытии этого свойства, его моделировании ныне кровно заинтересована бионика, пытающаяся внести свой посильный вклад в решение одной из важнейших современных проблем, которую кратко именуют "человек-машина".
Представьте себе такую гипотетическую ситуацию.
Скорая помощь привезла в больницу тяжелобольного. Человека положили на операционный стол. Положение чрезвычайно серьезное, дорога буквально каждая секунда: хирург должен сейчас, сию минуту принять решение, а диагноз заболевания еще далеко не ясен. Остается одно - обратиться за помощью к имеющейся в больнице диагностической вычислительной машине, в "памяти" которой накоплен огромный опыт врачей многих стран и поколений. За доли секунды она может "просмотреть" тысячи историй болезни, найти аналогии и на основе их анализа поставить абсолютно точный диагноз. И даже дать рекомендации по лечению. Хирургу нужно задать всего лишь один вопрос своему электронному консультанту. Только машина может дать единственно правильный ответ, и она может сообщить его почти мгновенно. Получив точный диагноз, выиграв время, можно приступать к операции...
Но... Существующие сейчас электронные вычислительные машины, находящиеся на вооружении промышленных предприятий, научно-исследовательских организаций, больниц и клиник, глухи и слепы! Всю информацию они собирают на ощупь, с продырявленных - перфорированных - карточек и лент. С электронными вычислительными машинами мы разговариваем не на своем языке, не так, как удобно нам, а так, как удобно им, машинам. Здесь принята сложная система программ, специальных машинных языков. Машинный язык - язык цифр. Какую бы задачу, вычислительную или логическую, ни решала бы быстродействующая электронная вычислительная машина, она совершает операции над цифрами и только над ними. Тысячи математиков и программистов заняты составлением алгоритмов и программ для машин, или, иными словами, переводом рабочих заданий с языка человеческого на язык машинный. Представьте себе бригаду землекопов, насыпающих по лопатке ковш гигантского экскаватора, - нечто подобное происходит и в современных вычислительных центрах. В нашем же конкретном случае вопрос хирурга попадает в диагностическую машину не раньше чем через час - время, требуемое для кодирования вопроса и перфорации ленты или карты. А час - это очень много, когда приходится сталкиваться с цейтнотом в "игре", где ставка - жизнь. Вот и приходится врачу в подобных случаях надеяться лишь на собственный опыт да интуицию.
Таких или подобных ситуаций, когда возможности, заложенные в машинах, не удается использовать из-за трудности общения с ними, можно назвать десятки и сотни. Так как электронные вычислительные машины не понимают нашего языка и не могут на нем говорить, не возможны ни разговор с ними по телефону, ни приглашение электронного консультанта на консилиум, на совещание, где порой приходится оперативно принимать решения по важнейшим техническим и экономическим вопросам, на непринужденную беседу с иностранцем, языком которого вы не владеете. Но, пожалуй, самое главное - разговор с вычислительными машинами совсем не прост, сегодня для этого необходимо в совершенстве знать программирование и машинный язык.
Постепенно в науке наметился путь решения этой проблемы: нужно создать машины, понимающие язык человека, такие машины, которые могли бы слышать и понимать услышанное, подчинялись бы буквально каждому нашему слову. Создание машин, воспринимающих голосовые команды, значительно облегчило бы деятельность человека-оператора, так как отпала бы необходимость перекодировки словесно выраженных понятий и команд в сложно координированные акты клавишного или кнопочного управления. Научив машину слушать и понимать нашу речь, мы смогли бы не только улучшить обмен информацией между человеком и машиной, но и эффективно использовать последнюю для совершенствования контактов между людьми. Как, например, услышать человека, опустившегося на дно моря, как быстро и правильно обучить людей чужим языкам? На все эти вопросы мы могли бы, вероятно, получить ответы у машины, которая научилась бы понимать нас "с полуслова".
Каковы же место и роль бионики в решении проблемы "человек - машина"?
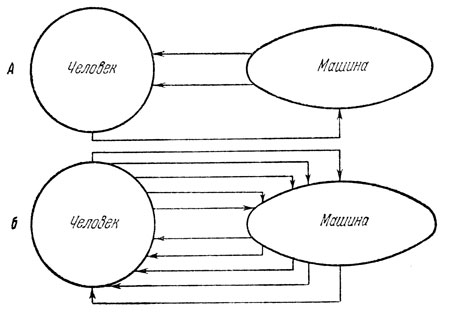
Рис. 5. Схема обмена информацией между человеком и машиной (по В. В. Ларину). А - современное положение дела: человек получает от машины только зрительные и слуховые сигналы и дает машине команды только путем двигательных актов; Б - перспективы расширения поступления информации от машины к человеку и обратно через не используемые сейчас анализаторы (осязание, проприоцептивная чувствительность и т. д.)
В настоящее время обмен информацией между человеком и машиной осуществляется по сравнительно небольшому числу каналов, главным образом посредством выполняемых двигательных актов: нажатием кнопок, ключа телеграфного аппарата, клавиш, перемещением рычагов, педалей, поворотом рулевого колеса и т. п. Что же касается информации, поступающей от машины к человеку, то она сводится лишь к звуковым и световым сигналам (включение различных табло, цифровая индикация). Между тем возможности связи человека с машинами значительно обширнее, чем это имеет место сейчас (рис. 5). Достаточно напомнить, что, кроме зрения и слуха, человек обладает обонянием, осязанием, вкусом, а также проприоцептивной чувствительностью. Все эти входы живой системы - человека - могут весьма успешно использоваться для ввода в машину самой разнообразной информации. И бионика идет именно по этому пути. В целях обеспечения наилучшего общения человека с машиной бионика пытается широко использовать биологические принципы в технике. Иными словами, в отличие от кибернетики и инженерной психологии, пытающихся разработать оптимальные методы использования человеческих возможностей для управления сложнейшими техническими системами, бионика идет по пути улучшения связи человека с машиной не за счет рационализации человеческих качеств, а за счет "биологизации" машин. Примером может служить проводимая в настоящее время работа по созданию "слышащих" машин.
Такую машину нужно прежде всего снабдить отличным слуховым аппаратом. Это задача, так сказать, номер один. Но услышать сообщение - распознать "слуховые образы" - еще полдела. Нужно также научить машину "понимать" его смысл - в противном случае автомат превратится в некое кибернетическое подобие гоголевского Петрушки, который, как известно, отличался тем, что все читал с равным вниманием. Его увлекал сам процесс чтения: "... что вот-де из букв вечно выходит какое-нибудь слово, которое иной раз черт знает что и значит". "Научить" машину "понимать" человеческую речь - задача номер два. Обе задачи неотделимы друг от друга - это типичные бионические проблемы.
Итак, бионический аспект рассматриваемой нами проблемы "человек - машина" ("человек - автомат") заключается в поиске новых путей для построения машин (автоматов), наилучшим образом согласованных с человеком-оператором. Задача состоит в создании своеобразного симбиоза человека и машины, т. е. такой их кооперации, при которой машина будет выполнять устные команды, заданные инструкции или выдвигать гипотезы и доказывать их, а человек - оценивать их и давать новые распоряжения или инструкции. Процесс общения человека с машиной нельзя разделять. Для достижения этого нужно усовершенствовать (формализовать) обычный язык так, чтобы каждое сообщение человека при его связи с машиной имело для нее определенный логический вес. В этом направлении уже получены некоторые результаты.
По сообщениям американской печати, датированным январем 1962 г., в Корнельском университете был разработан первый перцептрон "Тоберморей", способный "опознавать" произносимые слова. Система памяти этого экспериментального перцептрона содержала около 1000 ячеек, а электроакустический преобразователь (микрофон с последующей записью на магнитную ленту) принимал до 1600 отдельных акустических сигналов. Почти одновременно или немного позднее сотрудники Иллинойского университета разработали динамический преобразователь сигналов для выделения инвариантов, т. е. неизменных частотных составляющих, служащих основой данного звука речи. Этот прибор содержит систему фильтров и дифференцирующих цепей, при помощи которых производится разложение звуков на частотные составляющие и выделение инвариантов. Создатели прибора считают, что он может быть использован для разработки системы автоматического опознавания слов, а также для предварительной обработки данных в адаптивных системах.
Значительная и даже, пожалуй, основная часть исследований, проводимых в США в области распознавания речи, посвящена созданию квазислуховых автоматов для военных целей. Так, по контракту с Министерством обороны США одна фирма разработала "обучающуюся" машину "Кибертрон" типа К-100, предназначенную для распознавания сигналов гидролокационного устройства. Процесс самообучения проводится путем сравнения записей на перфоленту блока памяти сигналов, создаваемых звуколокационным устройством, с последующей записью других сигналов, например сигналов, создаваемых надводным кораблем, которые по своему частотному спектру близки к сигналам от подводных лодок. Машина сравнивает эти сигналы и выдает ответ. Процесс повторяется до тех пор, пока ответ не будет правильным. Обученная таким образом система, по сообщениям американской печати, обеспечивает быстрое и правильное распознавание шумов, подводных лодок с ошибкой не большей, чем у самого опытного оператора гидролокационной станции. Кроме машины типа К-100 фирма разработала другой вариант - "Кибертрон" типа К-200, предназначенный для распознавания слов английской речи.
Сегодня оператору и диспетчеру приходится не только наблюдать, но и активно вмешиваться в производственные процессы, регулировать, управлять ими. В таких случаях управление голосом могло бы существенно облегчить работу. Учитывая это, в нашей стране и за рубежом в последние годы разработан ряд устройств, срабатывающих при произнесении заранее определенных командных слов. Так, например, несколько лет назад в Институте электроники, автоматики и телемеханики Грузинской ССР была создана экспериментальная тележка несколько необычной формы. Ученые научили ее выполнять 7 слов-команд. Как удалось им достичь этого? Если одно и то же слово повторять много раз и притом разными голосами, а затем изучить сделанную запись, то можно найти общие черты, характерные только для данного слова. Составленная на основе такого исследования схема закладывается в машину. И тогда, принимая через микрофон уже знакомые ей сигналы, она реагирует на них включением вполне определенных приборов. Повинуясь командам оператора, металлическая тележка срывается с места и послушно движется вперед, поворачивает налево или направо и по сигналу "стоп" мгновенно останавливается. А ведь вместо металлического зверька легко себе представить "понимающих" устные команды-приказы прокатные станы на заводе, работающие в поле тракторы и любые другие машины.
Интересно отметить и такую деталь: изображение звука так же постоянно для каждого человека, как и отпечатки его пальцев. Криминалисты на Западе уже пытаются использовать это обстоятельство для опознания преступников. А ученые Грузии намерены на этой основе создать машины, выполняющие команды только определенных лиц. В общем, как в сказке: "Сезам, откройся!"
Из литературы известно о создании устройства, производящего по устной команде перестройку радиоприемников на фиксированные волны. Создано также несколько моделей машин для автоматического набора номера телефона голосом. Правда, большинство из них хорошо работает только при настройке на данный голос, причем точность набора составляет в этом случае 97-99%, но без настройки она падает до 50 - 70%.
Изготовлены выключатели, реагирующие на резкие звуковые команды. Оказывается, человеческий голос обладает интересным свойством, называемым "асимметрией огибающей". Особенно большой асимметрией обладают гласные звуки. Прибор, основанный на этом свойстве, "слышит" резко сказанные слова или крик и отключает (в случае опасности) двигатели или другие агрегаты. И вот еще что важно: это устройство способно реагировать на речевые сигналы, которые в 20 раз слабее, чем окружающий шум, - шумы не обладают асимметрией огибающей.
Один из зарубежных институтов разработал станок с программным управлением. От других подобных конструкций этот станок отличается тем, что программу для него составляет электронная счетная машина. Точнее, она не составляет программу, а преобразует в понятную для станка цифровую форму команды, отдаваемые оператором в микрофон (на это уходит всего несколько секунд). Станок, программируемый голосом, позволяет сэкономить время, нужное для перевода величин подачи, глубины резания и т. д. в машинный код, -устройство само выполняет эту работу. Разумеется, программу можно наговорить и заранее, тогда станок будет обрабатывать деталь сам, без оператора. Конструкторы сделали так, что электронной вычислительной машине "безразлично", каким голосом отдается приказ: громким или тихим, басом или дискантом. Ее не смутит и различная интонация, особенное произношение и даже акцент. На входе устройства, управляющего работой станка, стоит "швейцар". Он пропускает только самую суть слова (т. е. то, что отличает данную команду от другой, например "два" от "три" и т. д.). А всяческие "украшения" - то, что ученые называют избыточной информацией, - попросту не воспринимаются машиной.
Не так давно на Брюссельской автомобильной выставке демонстрировался автомобиль фирмы "Крейслер", управляемый посредством устных распоряжений. Стартер запускал мотор, повинуясь словесному приказу водителя. Устное распоряжение заставляло машину включать и выключать сцепление, переключать скорости. Даже повороты водитель совершал, не прикасаясь к рулю (его вовсе не было на машине!), а лишь произнося условные сигналы. Объемистый багажник автомобиля был весь заполнен электронной аппаратурой, среди которой первое место занимало счетно-решающее устройство и "рецепторы", воспринимающие акустические сигналы.
При разработке различных устройств, управляемых голосом, не остались забытыми и устройства для космонавтов. Так как у космонавта, вышедшего в космос из кабины своего корабля, "не хватает рук" для управления индивидуальным ракетным двигателем - он будет занят выполнением различных операций (работа с инструментами, кино- и фотокамерами и т. п.), - американские инженеры разрабатывают электронное устройство, с помощью которого это управление будет осуществляться командами, подаваемыми голосом космонавта. Для этого, как полагают конструкторы, будет достаточно 10 команд.
В Институте кибернетики Академии наук УССР, в лаборатории, руководимой В. А. Ковалевским, создана машина, "запомнившая" два десятка слов. Она узнает их почти безошибочно, независимо от того, кто их произносит. Если учесть, что из двух десятков слов можно составить не одну сотню разнообразных сочетаний, то выходит, что уже сегодня машина в состоянии воспринимать несколько сот различных голосовых команд. Спору нет, этого слишком мало, чтобы вести с машиной свободную беседу, но достаточно для того, например, чтобы она могла мгновенно "понять" команду о выходе из какой-либо аварийной ситуации.
Из всего приведенного выше следует, что разработка устройств, управляемых голосом человека, идет в определенном направлении. Однако до сих пор еще не созданы устройства для ввода любого речевого сообщения в вычислительные машины. Пока ведутся только научные поиски, эксперименты, ведь совершенно ясно, что поставленная задача много сложнее проблемы опознавания зрительных образов. Преодолеть языковую пропасть между человеком и машиной одним прыжком очень трудно.
Речь состоит из слогов, слов, фраз и т. д. Наименьшим элементом речи является звук (фонема). С физической точки зрения звуки речи различаются и частотным составом, и интенсивностью, и продолжительностью. В речи нет четких границ между звуками. Так же как рукописные буквы соединяются друг с другом промежуточными элементами, звуки речи в словах стыкуются с помощью "переходов" - звуков, которые возникают при перестройке нашего голосового аппарата для произнесения очередного звука. У разных людей форманты даже одних и тех же гласных звуков несколько разнятся по своей частоте и интенсивности (в детском и женском голосе все форманты несколько выше, чем в мужском). Кроме того, даже у одного и того же человека форманты одного и того же звука заметно различаются в зависимости от того, в каком слове произносится звук, ударный он или безударный, высок он или низок. Важной характеристикой звуков являются также число и частота обертонов. Индивидуальные особенности характеристик формант, а также присутствие в голосе еще и других специфических для каждого человека обертонов придают голосу человека неповторимый, присущий только ему одному тембр. Все это многообразие особенностей речевого сигнала заставляет ученых идти различными путями в поисках оптимального решения задачи распознавания речи.
Долгое время считалось, что в машинную память следует закладывать все признаки, которые в интересующем нас образе встречаются чаще всего. Однако при таком статистическом подходе вычислительная машина должна перерабатывать огромное количество сведений о множестве признаков. Но человек никогда не решает так задачу распознавания. Он сразу же выхватывает главное. При этом он выбирает всякий раз особую, часто очень сложьгую, но всегда наиболее эффективную тактику отбора. То же происходит и при распознавании речи (устной или письменной). Мы не отыскиваем каждый раз в памяти фонемы, не сличаем их с услышанными. Нам достаточно небольшого числа опорных ориентиров (первые звуки, ударение), чтобы понять слово. Мы часто понимаем и с "полуслова". Забывая об этом, машину учили постепенно составлять слова, последовательно складывать их из запасенных в памяти фонем. Вот почему, по мнению ряда ученых, практически никто не добился до сих пор большого успеха. Пока есть только машины, слушающиеся небольшого количества совершенно определенных устных команд, но не машины, в совершенстве "понимающие" речь.
Однако такого мнения придерживаются далеко не все специалисты, занимающиеся проблемой распознавания речи. Наоборот, опираясь на свои исследования, они считают, что восприятие слов в нашем мозге происходит по фонемам, а наличие автоматизма в приеме объясняется тем, что в памяти человека имеется набор слов и после прихода цепочки фонем (звуков) в мозгу автоматически создается соответствующий образ. "Это явление, - пишет М. А. Сапожков, - аналогично, например, печатанию на пишущей машинке: машинистка не может точно сказать, какие буквы были ею напечатаны, а при прочтении слова в мозге оно автоматически разлагается на буквы, и соответствующие сигналы поступают из мозга в пальцы. Следовательно, наиболее вероятно, что в мозге происходит опознавание фонем, а уже по ним - узнавание слов по образцам, хранящимся в памяти человека".
А вот Л. А. Чистович, А. В. Кожевников и другие сотрудники Института физиологии имени И. П. Павлова считают, "...что фонемы не представлены в акустическом потоке непосредственным образом и в процессе восприятия речи переход от акустического сигнала к символам фонем осуществляется иным, более сложным способом, чем это предполагает гипотеза пофонемного распознавания". Исследования Л. А. Чистович и В. А. Кожевникова показывают, что наша речь разбивается совсем не на фонемы, как это представляется многим. Письмо дробится на буквы, поэтому и в устной речи понятия, слова мы привыкли связывать с серией отдельных звуков. Но внутренняя организация устной речи другая: она разбивается не на фонемы, а на слоги. Человек принимает решение о предыдущей фонеме только после анализа последующего звука, т. е. он должен проанализировать весь слог.
Так как "...слог является той минимальной единицей, на уровне которой возможен переход от акустического сигнала к смыслоразличительным элементам языка", Л. А. Чистович и В. А. Кожевников пытаются организовать понимание машинами слов, или, как говорят, "распознавание образов речи", исходя из нового принципа. Они считают, что для машины различительными единицами должны были бы служить слоги. Тогда весь непрерывный поток устной речи можно разбить на слоговые группы и обрабатывать их, основываясь на звуках, которыми заканчиваются слоги. Как только начат переход к другому слогу, машина приступает к обработке данных о предыдущем, а затем передает полученные результаты в устройство памяти или на выход.
Быть может, следует идти по пути создания устройств, автоматически распознающих целые слова и фразы? О распознавании фраз речь может идти только в очень узком понимании: распознавание некоторых команд. Такой путь опознавания образа целого сообщения, по мнению ряда ученых, вполне себя оправдывает в том случае, когда дело идет об автоматизированном распознавании ограниченного набора (до нескольких десятков) команд, состоящих из одного-двух слов. Однако при переходе от ограниченного набора сообщений к общему случаю, когда число возможных речевых сообщений можно принять равным, например, числу осмысленных предложений на данном языке, рассматриваемый путь опознавания образа каждого отдельного сообщения, по мнению В. А. Кожевникова и Л. А. Чистович, явно не рационален. И действительно, для того чтобы хранить в памяти образы всех возможных предложений, распознающему устройству понадобился бы совершенно невероятный объем памяти. Как показывают произведенные Миллером, Галантером и Прибрамом расчеты, для того чтобы хотя бы один раз прослушать все грамматически возможные английские фразы длиной до 20 слов, человеку пришлось бы слушать примерно по 3 o 1020 фраз в секунду в течение 100 лет без перерывов!
Что касается обучения машин распознаванию целых слов, то сторонники фонемного метода рассуждают так. Каждый человек, говорящий по-русски, использует для передачи сообщений около 40 основных звуков-фонем и примерно 10 000 слов. Так что же легче - научить машину различать 40 фонем или десятки тысяч слов? "Как показывает опыт, - говорят специалисты, - идентифицировать фонемы трудно, но все же это единственно разумное решение".
Как мы видим, среди ученых нет единого мнения относительно выбора оптимального метода автоматического распознавания речи. И в этом нет ничего удивительного. Ведь до сих пор нам неизвестны инвариантные признаки фонем, по которым происходит их опознавание. Более того, неизвестно точно, опознаются ли элементы речи по фонемам, образы которых накоплены в памяти человека, или в памяти заложены образцы слов с их окончаниями и приставками и по этим образцам опознаются слова.
"Наивысшим и совершеннейшим человеческим приспособлением" назвал звуковую речь человека выдающийся русский физиолог И. П. Павлов. Физическая природа звуковой речи хранит в себе множество тайн. Как образуются звуки в голосовом аппарате человека, как они воспринимаются слухом и от чего зависит характер звука - вот проблема, в центре которой еще по сей день скрещиваются интересы ученых, работающих в самых разнообразных областях науки. Для того чтобы машины могли безошибочно выделять какой-то один образ из множества других сходных, нужно точное знание характерных его признаков. Но как выбрать такие признаки? Над решением этой задачи во всем мире ныне работают физиологи и лингвисты, акустики и невропатологи, специалисты по бионике и логопеды, психологи и инженеры, математики и конструкторы. Объединенные усилия всех этих специалистов, надо полагать, в конце концов раскроют тайны устной речи, дадут нам достоверные сведения о механизмах речи, о том, как мы говорим и слышим, почему понимаем слова.
А пока? А пока каждый ученый, работающий над созданием устройств по автоматическому распознаванию речи, идет избранным им путем.
Для проверки того или другого принципа автоматического распознавания речи ученые обычно строят фонетограф. Его блок-схема выглядит так: микрофон - усилитель - распознающееустройство - электрическая пишущая машинка. Появление фонетографов навело ученых на такую мысль: а что, если использовать это устройство в качестве самой обыкновенной пишущей машинки? Диктовать в микрофон текст доклада или научной статьи и получать на выходе тот же текст отпечатанным? Так сказать, автоматизировать труд машинисток или стенографисток, а может быть, и работу типографских наборщиков. Такой аппарат мог бы оказать неоценимую услугу также сотрудникам вычислительных центров. Они смогли бы вводить данные в вычислительную машину, просто диктуя их в микрофон.
Небезынтересно отметить, что возможность создания автоматического стенографа - пищущей машинки была доказана еще в начале сороковых годов советским ученым профессором Л. Л. Мясниковым, построившим динамический анализатор - прибор для объективного распознавания звуков речи. Однако реализация этой идеи была отложена из-за начавшейся Великой Отечественной войны.
Над созданием пишущих машинок-автоматов, печатающих под диктовку, ныне работают ученые ряда стран. Можно проектировать машинки, печатающие с голоса, для печатания слов, слогов, букв или звуков (фонем). По сложности конструкции и трудоемкости изготовления эти устройства очень разнятся. Так, для словесных машинок требуется очень большая память и само печатное устройство получается сложным и громоздким. Зато чисто фонетическая машинка должна содержать в памяти около 40 знаков и иметь столько же печатных знаков. Но такие устройства обладают чрезвычайно существенным недостатком: для чтения напечатанного материала требуется определенный навык, так как фонетографы дают на выходе фонетическую запись, т. е. значки, соответствующие звукам речи, а не буквам продиктованного текста, - своего рода транскрипцию. Почему же они непохожи друг на друга?
Дело в том, что произносимые звуки не соответствуют буквам русского алфавита. Сорока фонемам русской речи соответствуют 33 буквы алфавита. Помимо того, что в нашем алфавите есть непроизносимые буквы (ь, ъ), но и пишем-то мы часто совсем не то, что слышим. Произнесите, например, слово "лоб". На конце отчетливо слышится "п". Но если вы напишите так, как слышите, вас сочтут неграмотным.
Займись наши ученые проблемой распознавания речи не 15 - 20 лет назад, а во времена Кирилла и Мефодия - положение было бы совсем другим. И вот почему. 13 веков назад Кирилл и Мефодий создали русскую письменность, в которой каждому звуку соответствовала буква. Но за прошедшие 1300 лет в нашем произношении произошли большие изменения, а эволюция фонетической системы языка не получила достаточного отражения в письменной речи. Вот и получается описанная выше ситуация.
Как же заставить фонетическую машинку выполнять работу по перекодированию звуков в буквы подобно тому, как это делает пишущая под диктовку машинистка? Да и возможно ли это вообще? Возможно. Перевод звуков речи в буквы должен происходить в соответствии с грамматическими, орфографическими и лексическим:и правилами. Для ЭТОГО машинка должна быть наделена "памятью" на определенное количество звуков, сочетаний или слогов. Отсюда, конечно, не следует, что в памяти машинки должны быть заложены все звукосочетания, вполне достаточно иметь наиболее ходовые и типичные звукосочетания, при произнесении которых возможен неточный перевод звуков в буквы. Очень редких сочетаний или сочетаний, легко распознаваемых машинкой, может в памяти и не быть, так как это не вызовет трудностей в чтении материала и легко может быть исправлено в процессе чтения.
Примером удачного решения задачи является фонетическая пишущая машинка, созданная американскими учеными Г. Олсоном и Г. Беларом. Общий вид ее конструктивного оформления показан на рис. 6.
Блок-схему всего устройства можно рассматривать как сложный аналог слухового аппарата, части мозга, нервной системы и нервно-мышечного аппарата человека, печатающего под диктовку. Бионическая схема человека, печатающего под диктовку, и блок-схема фонетической пишущей машинки показаны на рис. 7. Чтобы понять принцип работы устройства, проследим, каким образом перерабатывается звуковая информация по пути ее следования.
Звуковая энергия улавливается наружным ухом человека, передается по слуховому проходу и воздействует на барабанную перепонку среднего уха. Механическое движение последней передается жидкости, заполняющей улитку (внутреннее ухо), при помощи слуховых косточек, которые, подобно рычажкам, перемещаются нелинейно. При этом происходит "компрессия" ("сжатие") сигнала, т. е. большие амплитуды уменьшаются сильнее, чем малые, причем уменьшение амплитуды пропорционально ее величине.
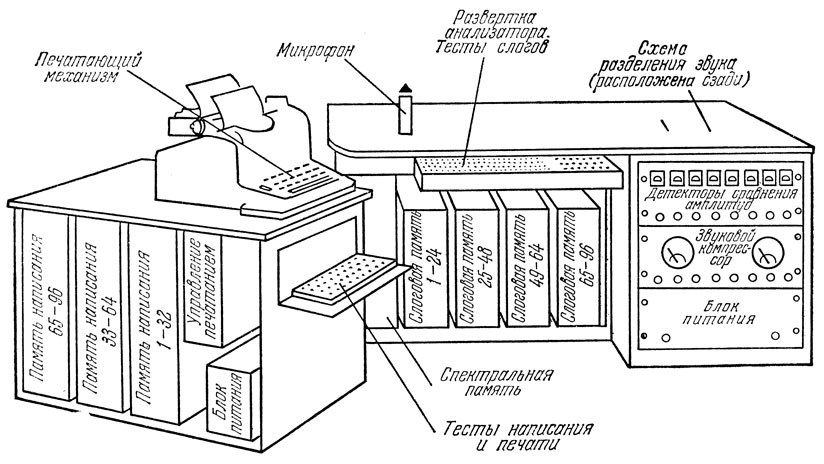
Рис. 6. Общий вид фонетической пишущей машинки (модель III), разработанной Г. Олсоном и Г. Беларом
На рис. 7 показано схематическое изображение "развернутой" улитки и показаны частоты, воспринимаемые различными ее участками. Здесь осуществляется первичный анализ информации. Дальнейший ее анализ происходит в мозге, куда сигналы поступают по слуховому нерву. На основе этого анализа мозг вырабатывает команды, посылаемые мышцам руки, нажимающей на соответствующие клавиши пишущей машинки.
В машине, распознающей речь, голос оператора воспринимается микрофоном и преобразуется в электрические колебания соответствующих частот. Желательно, чтобы результаты распознавания не зависели от громкости произносимых слов и расстояния от микрофона. Для этой цели в машине применен звуковой компрессор, представляющий собой специальный нелинейный усилитель, который хорошо имитирует работу среднего уха.
После усиления и компрессии речевой сигнал поступает на анализатор частот - систему из восьми полосовых фильтров, охватывающих диапазон 250-10 000 гц, и систему детекторов сравнения амплитуд. Последняя собрана так, что реле, соответствующее данному каналу, включается лишь тогда, когда уровень в нем больше среднего уровня в двух соседних каналах. Выходной сигнал частотного анализатора поступает в виде двоичного восьмиразрядного кода в корректированную по времени "спектральную память". В ней запоминаются состояния восьмиканальных реле в течение пяти последовательных интервалов времени. Образующаяся матрица 5X8, соответствующая произнесенному слогу или слову, считывается устройством распознавания комбинации сигналов лишь тогда, когда вся матрица будет полностью образована.
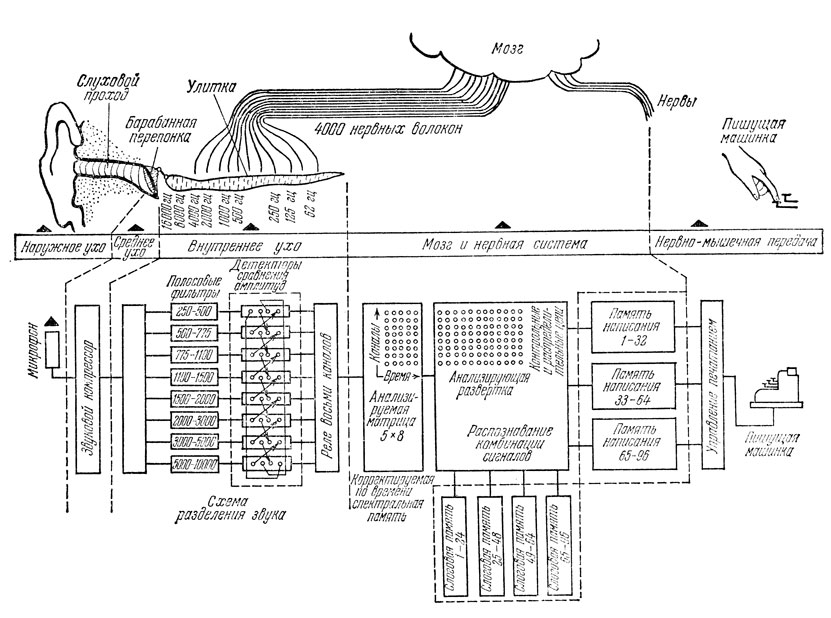
Рис. 7. Бионическая схема человека и машинки, печатающей под диктовку
Речь опознается по группе фонем, составляющих слог, а не по отдельным фонемам (причина этого заключается в том, что распознавание многих фонем вне контекста очень трудно). В слоговой памяти хранятся комбинации сигналов, соответствующие различным произношениям одного и того же слога или слова. Осуществляемое устройством распознавание 40-битной матрицы, соответствующей произнесенному слогу, представляет собой определенный вид процесса сравнения с имеющимися в слоговой памяти "эталонными" матрицами звукосочетаний.
Распознавание слога, если оно произведено, вызывает срабатывание того реле из памяти написания, которое связано с написанием данного слога. В памяти написания (орфографической памяти) имеются типовые комбинации сочетаний букв, представляющих 40 фонем, для заданных 100 слогов. Реле соединено с шинами очередности следования букв и с шинами кода букв в блоке управления печатанием, который в свою очередь управляет работой буквенных приводов. Наконец происходит печатание выбранных букв.
Таким образом, слово печатается в соответствии с заранее определенным написанием, которое по необходимости должно быть одинаковым для одинаково звучащих слов. Именно поэтому устройство и было названо "фонетической пишущей машинкой".
По данным Г. Олсона и Г. Белара, для того чтобы в английской речи понять 98% произносимых слов и фраз, достаточно иметь "память" приблизительно на 2000 слогов. При этом орфография оказывается правильной примерно в 85% случаев. По расчетам М. А. Сапожкова, для русской речи нет необходимости в таком объеме памяти, так как фонетическая и печатная формы русских слов различаются в значительно меньшей степени, чем английских (требуется память менее чем на 300 звукосочетаний типа СГ и ГС и около 100 звукосочетаний со сложными консонансами).
Несколько моделей машинок, пишущих с голоса, сконструировал научный сотрудник Женевского университета Дрейфус-Граф. Текст читают в микрофон. Звуки, из которых состоят слова, анализируются электронным "мозгом", и каждый звук превращается в электрический сигнал. Эти сигналы приводят в действие рычаги электрической пишущей машинки. Как утверждает изобретатель, последнюю модель его пишущей машинки можно "научить" писать со скоростью стенографистки высшей квалификации.
Над созданием пишущих машинок, печатающих под диктовку, работают и советские ученые ряда научно-исследовательских организаций. Достигнутые в последние годы успехи в этой области позволяют надеяться, что в ближайшее время появятся сначала промышленные образцы фонетических машинок, затем будет организован серийный выпуск пишущих машинок-автоматов, обеспечивающих правильную орфографию. А отсюда уже один шаг до устройств, которые станут составной частью переводческих машин. Когда же наши машины в достаточной степени обогатят свой словарный запас - а это время, надо полагать, недалеко, - они смогут производить синхронный перевод на несколько иностранных языков.
Впрочем, автомату-переводчику придется различать не только чужую речь, но и говорить самому.
Однажды Норберт Винер сказал:
"Вполне возможно, чтобы человек разговаривал с машиной, машина - с человеком и машина - с машиной".
С тех пор прошло около 20 лет. Первая часть предвидения ученого близка к осуществлению. А что делается или что уже сделано ныне для реализации второй части предсказания отца кибернетики о возможности разговора между машиной и человеком?
"Я спросил:
- Были вы рады дождю, который прошел сегодня после полудня? Он ответил:
- Нет, я люблю больше солнечную погоду.
- В жаркую погоду человеку нужна по крайней мере одна ванна в день, - заметил я.
- Да, я как раз был на улице и изнемогал от жары, - последовал ответ.
- Когда придет рождество, будет холодная погода, - глубокомысленно заметил я, пытаясь поддержать разговор.
- Холодная погода? - переспросил мой собеседник.- Да, обычно в декабре морозно.
- Сегодня ясная погода, - гнул я свою линию.- Как вы думаете, долго ли она будет продолжаться?
- Позвольте мне не лгать, - взмолился мой собеседник, сбитый с толку столь противоречивыми высказываниями. Как же дождливая погода может быть ясной? "
Говорят, этот разговор состоялся в Университете в Торонто между канадским ученым Берклеем и электронной вычислительной машиной. В ее "память" ввели триста английских слов и научили поддерживать несложную беседу.
За достоверность приведенного диалога мы не ручаемся. Но если бы вы, читатель, лет пять назад заглянули в одну из комнат Института электроники, автоматики и телемеханики Академии наук Грузинской ССР, то вы бы увидели оригинальную экспериментальную машину, которую ученые назвали "синтезатором человеческой речи". Машина сама формировала отдельные звуки речи - фонемы - и, строго придерживаясь законов фонетики, составляла из них отдельные слова и даже целые фразы. И несмотря на младенческий возраст, она научилась говорить разными голосами - мужским, женским, детским. Она одинаково легко и внятно произносила одно слово "мама" и целую фразу на грузинском языке, которая в переводе означала: "Будь внимательна, дорогая Нона!" Этими словами машина напутствовала молодую грузинскую шахматистку Нону Гаприндашвили, когда та собиралась на международный турнир. Экспериментаторы научили машину четко произносить также несколько фраз на русском языке, например: "Наша машина училась, она узнала жизнь". Хоть все эти фразы были заложены в память машины в виде шутки, но за достоверность того, что она их внятно и четко произносила, мы ручаемся.
Аналогичные устройства, но со значительно большим словарным запасом разрабатываются сейчас в США и ряде других стран с использованием методов синтеза речи из слоговых и из фонемных сегментов. Оба метода пока конкурируют друг с другом. Для передачи фонемных сегментов служит созданное для применения в технике дальней связи устройство "Вокодер", в котором место микрофона занимает "пишущая машинка" для подачи электрических импульсов. Специально обученная машинистка нажимает на клавиши, соответствующие определенным фонетическим знакам. Скорость "печатания" должна быть равна скорости речи. Получается своеобразный "разговор руками". Для передачи слоговых сегментов применяют специальную перфорированную ленту с кодированными номерами сегментов. Эта лента подготавливается на буквопечатающем аппарате со слоговым анализатором, группирующим буквы в слоги и выдающим соответствующий номер сегмента. На приемном конце по сигналам, приходящим из памяти, выдаются в усилитель соответствующие сегменты, и синхронизатор объединяет их в слова. Качество речи пока получается недостаточно высоким из-за стыковых явлений.

Рис. 8. Видиограмма записи гласных у, о, а, э, ы, и (по А. Митронович-Моджеевской). Видны отдельные верхние тона
Применяются также синтезаторы речи, построенные на принципе синтеза речи по формантам и использующие электрический эквивалент речевого аппарата. Для их построения требуется устройство для перевода печатного текста в кодовые комбинации для управления эквивалентом речевого аппарата. Если повторяющиеся импульсы генератора подать на цепочку контуров, каждый из которых может настраиваться на соответствующую частоту, то удается создать довольно разборчивую искусственную речь.
Весьма распространенным является анализ звуков по данным динамических спектров видимой речи.
Принцип метода состоит в следующем. Изменение спектральных характеристик речевого потока исследуется при помощи динамических спектрографов "видимой речи". Анализатор "видимой речи" изображает речь в виде динамической картины изменения интенсивности во времени в частотных полосах - как распределение оптической плотности на фотографической пленке. Формантные области выделяются как области интенсивного почернения. Электроакустический анализ гласных при помощи динамического спектрографа "видимой речи" показан на рис. 8.
Если применить фотоэлемент, преобразующий изменения светового потока в изменения электрического тока, то можно получить электроакустическую картину изменения спектра во времени.
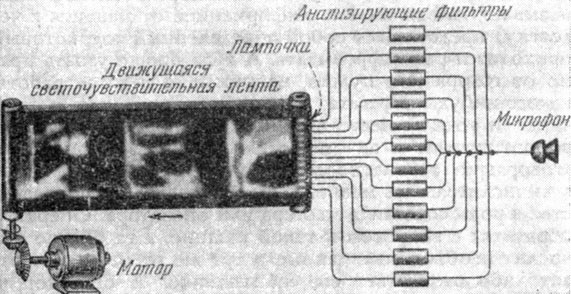
Рис. 9. Схема звукового спектрографа
На рис. 9 показана схема звукового спектрографа К. Поттера (1945 г.). Голос, поступивший в микрофон, пропускается через набор полосовых фильтров, и выходные напряжения каждой полосы используются для управления яркостью маленьких лампочек, излучение которых оставляет следы на движущейся светочувствительной ленте. В полученной записи по оси ординат - частота, по оси абсцисс - время, а интенсивность звука выражена плотностью почернения светочувствительной эмульсии.
Процесс обучения машины нередко сравнивают с обучением ребенка. Но ребенок, как известно, первым делом начинает понимать слова, потом учится говорить и лишь много позже - читать. С машинами пока что все происходит наоборот. "Работоспособные" читающие автоматы уже созданы, автоматы, умеющие слушать и распознавать человеческую речь, находятся в зените эксперимента, а вот говорящие машины пребывают еще в зачаточном состоянии. Сегодня диалог человека с машиной еще невозможен.
А для чего, собственно, нужен такой разговор?
Как уже говорилось выше, операторы и диспетчеры имеют ныне дело с большим количеством разнообразных сигналов, подаваемых на пульт управления. Одновременное наблюдение за многими приборами становится подчас затруднительным. Снижается быстрота реакции на сигналы, совокупность которых (ее принято называть, как вы знаете, информацией от машины к человеку) представляет собой определенный код, который приходится расшифровывать. А куда проще узнать прямо от говорящего пульта, например, о режиме работы какого-нибудь агрегата, машины, системы или о причинах и точном месте аварии, чем определять все это по оптическим и акустическим сигналам. Кроме того, "говорящие автоматы" могут войти составной частью в вычислительные машины, выступающие на производстве в роли советчика мастера или оператора. Оператор обратится с вопросом к такой машине, а та быстро вычислит необходимые данные и тут же голосом даст ответ либо отпечатает его на машинке. А оператор, в зависимости от обстановки, примет решение, как лучше, оптимальнее вести процесс.
Мы уже привыкли к тому, что, набрав по московскому телефону номер 100, слышим монотонный голос: "Десять часов две минуты". Это простейший говорящий автомат точного времени - автоответчик со сменными записями на магнитной ленте. Но скоро на помощь человеку придут справочные быстродействующие электронные машины - звуковые энциклопедии. По устному запросу человека (например, по телефону) машина мгновенно отыщет нужную информацию и ответит на вопрос из области науки, культуры, быта...
В дальнейшем, по-видимому, говорящие машины найдут широкое применение и в связи. Если из речи автоматически выделять на входе характерные признаки фонем и передавать только эти признаки, а на выходе по ним восстанавливать речь, то ширину канала связи можно сократить в несколько сот раз. Значит, по одной и той же линии сможет вести переговоры значительно большее число людей.
Пройдут годы, и к таинственным планетам солнечной системы устремятся пилотируемые космические корабли. Немало опасностей будет поджидать космонавтов, которые первыми увидят новые, неизвестные миры, и, вполне возможно, что разведчиками, предупреждающими людей о грозящих опасностях, будут говорящие роботы, роботы-друзья... "Здесь температура - 105°... Сюда можете ступать смело... Здесь зыбкая поверхность, обойдите..." - нечто подобное смогут услышать космонавты от передвигающихся впереди роботов и своевременно предпринять те или иные действия. Это пока еще фантастика. Но не так уж далеко то время, когда умеющие слушать и говорить машины будут помогать нам быстро и на большом расстоянии голосом управлять движением поездов и самолетов, подводных и надводных кораблей, тракторов и комбайнов, будут подавать команды автоматическим станкам, цехам-автоматам с единого диспетчерского пункта завода. Все это - завтрашний день нашей науки и техники.
Проблема распознавания и воспроизведения образов речи - одна из насущных проблем бионики и кибернетики. Сегодня мы находимся еще только в начале пути, и поэтому, разумеется, трудно сейчас предсказать, как будет организована система речи у будущих наших электронных собеседников. Но очевидно одно: если мы хотим, чтобы машина действительно понимала речь и говорила сама, ее нужно снабдить чем-то вроде второй сигнальной системы. Иными словами, необходимо создать нечто похожее на вторую сигнальную систему человека. Нет слов, эта работа предельно сложна и трудно осуществима. Однако следует признать: чем сложнее становится наше представление о грядущих электронных собеседниках и о нас самих, тем ближе и реальнее делаются эти будущие друзья-машины, умеющие нас слушать, понимать и говорить.
Мы привыкли к обыденности слов и подчас забываем о величии оружия, которым владеем. Но, подумав об этом, нельзя не восхищаться щедростью людей, стремящихся передать свои способности, свой интеллект машинам.
|
ПОИСК:
|
При копировании ссылка обязательна:
http://biologylib.ru/ 'Библиотека по биологии'