3. Нуклеиновые кислоты и синтез белка
Код жизни
Мы видели, как организм получает и хранит энергию, необходимую для его жизнедеятельности. Реакции получения и хранения энергии, как и сотни других реакций, протекающих в любом живом организме, катализируются ферментами*, и, следовательно, организм должен синтезировать эти ферменты.
* (Ферменты - это белки, каждый из которых характеризуется специфическими химическими свойствами и геометрическим строением. Не все белки являются ферментами. Некоторые из них, такие, как белки мышц и кожи, выполняют структурные функции и не обладают ферментативной активностью.)
Вообще для каждой отдельной реакции требуется собственный фермент. Например, фермент, катализирующий окислительное декарбоксилирование пировиноградной кислоты, отличается от фермента, катализирующего окислительное декарбоксилирование α-кетоглутаровой кислоты, хотя эти реакции очень похожи.
Следовательно, ферменты по своему каталитическому действию чрезвычайно специфичны, или селективны. Так как ферменты являются белками, высокая степень специфичности обусловлена главным образом последовательностью аминокислотных остатков в белковой цепи. Следовательно, организм должен быть способен синтезировать сотни определенных белковых молекул, каждая из которых обладает собственной, неизменной последовательностью аминокислотных остатков. Каждый фермент может содержать сотни остатков аминокислот, и каждая клетка должна содержать полную информацию, необходимую для пополнения запасов любого из ее ферментов, когда это требуется. Казалось бы, это слишком сложная задача для простого одноклеточного организма, каким является бактерия, и даже для такого сложного, состоящего из многих клеток создания, каким является человек, однако природа создала остроумную схему, следуя которой даже низшие организмы легко решают ее.
Какова же суть схемы? Каждая клетка содержит полный набор "проектов" для строительства своих ферментов. Эти проекты хранятся в ядрах клеток в виде молекул дезоксирибонуклеиновой кислоты (ДНК). Молекулы ДНК содержат планы создания специфических молекул белков. Когда клетке требуется та или иная белковая молекула, молекула ДНК изготавливает копию плана в виде молекулы рибонуклеиновой кислоты (РНК), называемой информационной, или матричной (мРНК).
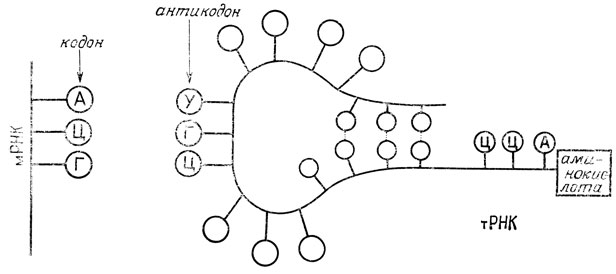
Информационная, или матричная РНК покидает ядро и начинает подбирать маленькие молекулы РНК другого типа, называемой транспортной РНК (тРНК). Эти маленькие молекулы тРНК связываются с определенными местами вдоль длинной молекулы мРНК. Каждая маленькая молекула тРНК несет определенную аминокислоту. Когда молекулы тРНК выстраиваются вдоль мРНК, оказавшиеся соседними аминокислоты связываются друг с другом с образованием пептидной связи. Когда образуется пептидная связь, аминокислоты освобождают тРНК, а тРНК в свою очередь освобождает мРНК. Полностью молекула белка будет синтезирована после того, как молекула тРНК побывает на всех участках мРНК, начиная с одного ее конца и постепенно перемещаясь до другого конца. Самым важным является то, что последовательность аминокислот в построенной молекуле белка будет точно задана последовательностью оснований (см. ниже) исходной молекулы ДНК ядра клетки (рис. 3.3).
Каким образом достигается такая точность? Многие детали этого процесса неизвестны до сих пор, но в основном тайна была раскрыта после того, как Френсис Крик и Джеймс Уотсон в 1953 г. предположили, что молекула ДНК должна иметь двухспиральную структуру.
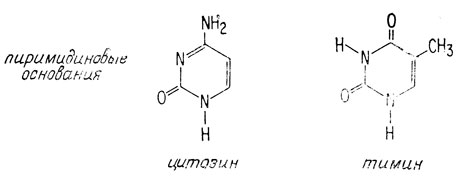
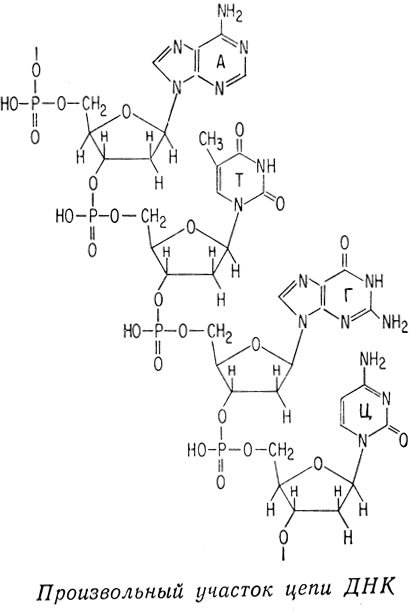
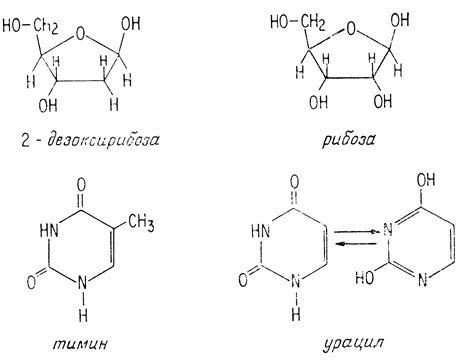
Молекулы дезоксирибонуклеиновых кислот представляют собой длинные цепочки, содержащие сотни нуклеотидов. Каждый нуклеотид состоит из пуринового или пиримидинового основания, молекулы 2-дезоксирибозы и фосфорной кислоты. Пуриновыми основаниями являются аденин или гуанин, пиримидиновыми - цитозин или тимин.
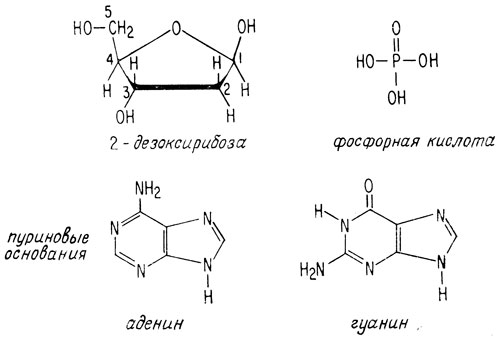
Полинуклеотид имеет сахаро-фосфатный остов, а пуриновые и пиримидиновые основания присоединены к остатку сахара по положению 1 (атом углерода альдегидной группы). Так как дезоксирибоза не имеет гидроксильной группы в положении 2, фосфорная кислота связывает углерод С-3 одного сахарного остатка с углеродом С-5 следующего сахарного остатка.
Пуриновые основания А - аденин, Г - гуанин.
Пиримидиновые основания Т - тимин, Ц - цитозин.
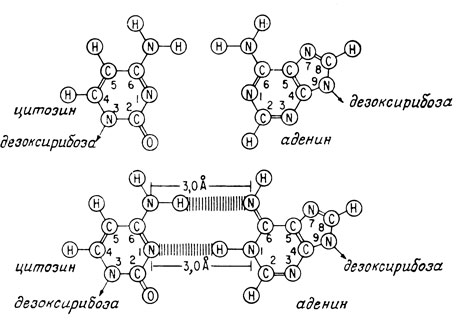
ДНК существует в ядрах клеток в виде спаренных нитей, закрученных в двойную спираль (рис. 3.1). Каждое пуриновое или пиримидиновое основание направлено внутрь спирали по направлению к ее оси и связано водородной связью с другим пуриновым или пиримидиновым основанием, находящимся на другой нити. Пуриновые основания всегда образуют водородную связь с пиримидиновыми основаниями, и наоборот. При этом вследствие донорно-акцепторной природы групп, образующих водородную связь, аденин всегда образует водородную связь с тимином, а гуанин - с цитозином. Следовательно, число остатков аденина всегда равно числу остатков тимина, а число гуаниновых остатков всегда равно числу цитозиновых остатков.
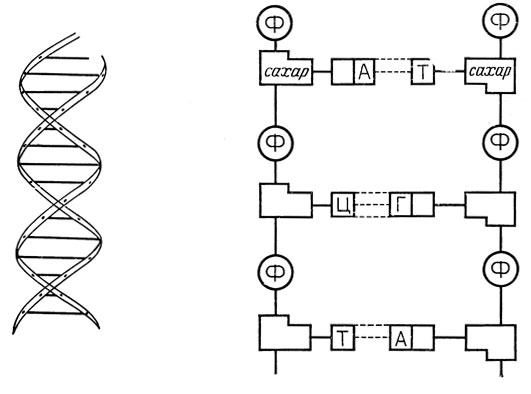
Рис. 3.1. Структура ДНК*. а - двойная спираль; б - спаривание оснований между нитями
* (В главе 11 мы будем обсуждать метод рентгенографии, который позволил Уотсону и Крику предложить структуру двойной спирали для молекулы ДНК.)
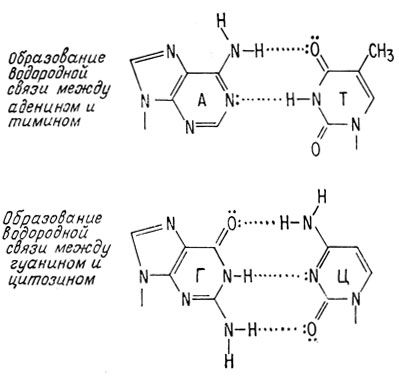
Основания в ДНК связываются посредством водородных связей. Водородные связи пары аденин-цитозин не столь стабильны, как связи пары аденин-тимин. Для того чтобы аденин и цитозин могли образовать водородные связи, необходимо, чтобы аминогруппа аденина, находящаяся в положении 6, претерпела таутомерный переход* в иминогруппу, как это показано ниже на диаграмме. Но эта конформация аденина опять не является стабильной.
* (Таутомеризадия - это процесс изомеризации, при котором протон перемещается от атома 1 к атому 3. В случае аденина в этот процесс включены следующие структуры:
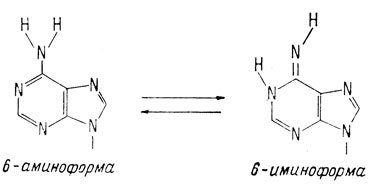
)
Следовательно, образование пары А-Т будет предпочтительнее образования пары А-Ц. Аналогичный подход можно использовать, чтобы показать, почему пара гуанин-цитозин предпочтительнее пары гуанин-тимин.
Строгое требование спаривания оснований важно потому, что оно обеспечивает механизм точного удвоения пары нитей. ДНК удваивается перед делением клетки, чтобы снабдить каждую из дочерних клеток полным набором молекул ДНК. Это происходит путем разрыва водородных связей между цепями и затем образования новых водородных связей с новыми нуклеотидными партнерами: аденина с тимином и гуанина с цитозином (рис. 3.2). Затем новые нуклеотиды образуют между собой сахаро-фосфатные связи, создавая новую цепь. Результатом является точное воспроизведение исходных спаренных цепей. Это и есть молекулярная основа наследственности. Любая ошибка в процессе удвоения вызывает мутацию.
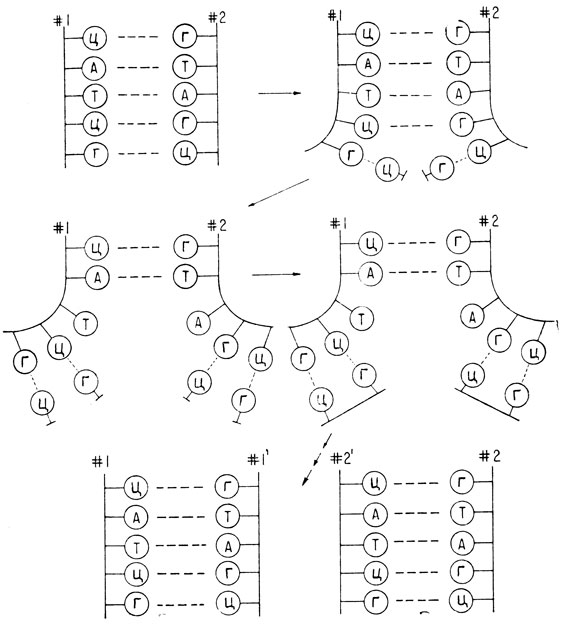
Рис. 3.2. Удвоение двухцепочечной молекулы ДНК
Процесс репликации ДНК более понятен, чем процесс синтеза молекулы мРНК. Основной тайной в синтезе мРНК является тот факт, что на каждой двухцепочечной молекуле ДНК синтезируется только одна нить РНК. Единственная образующаяся молекула мРНК является точной копией одной из цепей ДНК, но не другой цепи. Затем мРНК выходит из ядра и прикрепляется к рибосоме*.
* (Рибосомы - это большие сложноорганизованные частицы в цитоплазме. Они представляют собой глобулярные структуры, богатые белком и РНК, и являются местом синтеза белка в клетке. )
Молекула РНК подобна молекуле ДНК, за исключением того, что РНК содержит рибозу вместо дезоксирибозы и основание урацил вместо тимина (урацил является деметилированным тимином). Как и тимин, урацил всегда образует пару с аденином.
Остов структур ДНК и РНК одинаков, т. е. остатки фосфорной кислоты связывают положение 3 одной молекулы сахара с положением 5 другой молекулы сахара. Важным последствием наличия гидроксильной группы в положении 2 в остатке рибозы РНК является то, что она делает РНК значительно более чувствительной к мягкому щелочному гидролизу, чем ДНК. Причиной этого является участие гидроксила в положении 2 в щелочном гидролитическом расщеплении РНК.
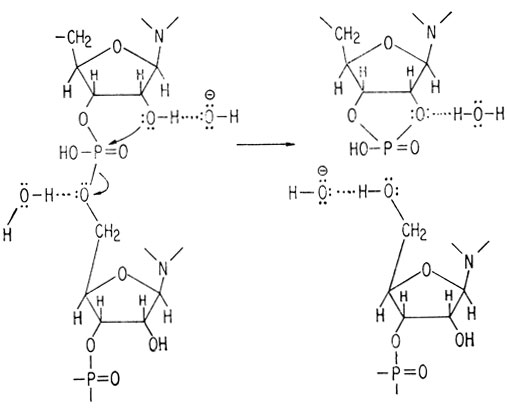
Это участие приводит к промежуточному циклическому 2′,3′-диэфиру*, который затем гидролизуется с образованием 2- или 3-фосфата. При щелочном гидролизе получаются оба фосфата, хотя сама РНК содержит свободную гидроксильную группу в положении 2.
* (В отличие от 2′,3′-диэфира, упомянутого выше, 3′,5′-циклический аденозинмонофосфат участвует в многочисленных проявлениях гормональной деятельности. Он участвует в стимуляции и (или) замедлении дыхательного цикла (гл. 2). За открытие роли этого соединения во многих жизненных процессах доктор Эрл Сазерлэнд был удостоен Нобелевской премии по медицине за 1971 г.)
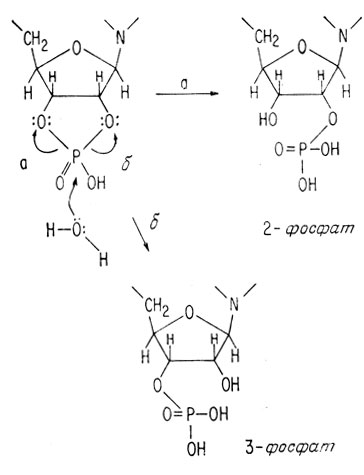
Так как молекула ДНК не имеет 2-гидроксила, такой тип взаимодействия во время гидролиза невозможен. Вследствие этого ДНК существует намного дольше РНК, а запас РНК должен пополняться в течение долгого процесса белкового синтеза.
В результате принципа комплементарного спаривания оснований молекула РНК точно отражает последовательность оснований в молекуле ДНК. Так, мРНК содержит остатки аденина там, где ДНК содержит тимин, остатки цитозина там, где ДНК содержит гуанин, гуанин там, где ДНК содержит цитозин, и остатки урацила там, где ДНК содержит аденин. Но как это трансформируется в специфическую последовательность аминокислотных остатков молекулы белка? Это и есть самая интересная часть загадки.
Последовательность оснований в мРНК должна каким-то образом контролировать последовательность соединения аминокислот при образовании молекулы белка.
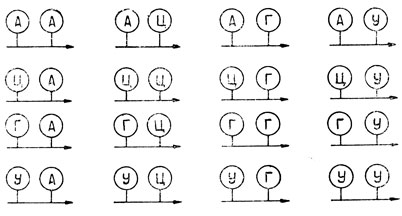
Информационная РНК содержит четыре типа оснований, а белок обычно содержит двадцать различных типов аминокислот. Поэтому отдельное основание не может контролировать положение определенной аминокислоты в белковой цепи, так как при этом четыре основания могли бы контролировать только четыре аминокислоты. Точно так же комбинации двух соседних оснований максимально могли бы контролировать шестнадцать аминокислот, так как возможны только шестнадцать различных комбинаций соседних оснований (см. ниже). (Комбинация АЦ отличается от комбинации ЦА вследствие направленности 3,5-диэфирной связи остатка фосфорной кислоты.)
Для того чтобы можно было осуществлять специфический контроль последовательности двадцати аминокислот, необходимо сочетание по крайней мере трех оснований информационной РНК, которая дает 64 возможные комбинации. Эти триплеты оснований на информационной РНК (называемые кодонами)
действуют как специфические места посадки для комплементарных триплетов, расположенных на молекулах тРНК* (антикодоны). Специфичность стыковки кодона и антикодона обусловливается специфичностью образования водородных связей между аденином и урацилом и между цитозином и гуанином. Комплементарные триплеты оснований тРНК находятся в так называемой антикодоновой петле вблизи середины цепи тРНК, а части цепи, не входящие в эту петлю, складываются, образуя двойную спираль по типу ДНК. Один из концов цепи всегда немного длиннее другого, и именно этот свободный конец несет аминокислоту. Прежде чем присоединиться к специфической молекуле тРНК, аминокислота активируется путем ферментативной реакции с АТФ, образуя связь между аминокислотой и аденозинмонофосфатом (АК-АМФ). Вызывает удивление тот факт, что этот свободный конец тРНК всегда имеет одну и ту же последовательность концевых оснований (ЦЦА) независимо от того, какая аминокислота находится на конце. (Аминокислота присоединяется к концевой рибозе через эфирную связь.) Ясно, что связывающий триплет должен каким-то образом контролировать выбор аминокислоты, присоединяемой к концу молекулы, однако, как это осуществляется, остается пока загадкой.
* (В ходе белкового синтеза в клетке тРНК оказывается связанной с мРНК, которая временно прикреплена к рибосоме (см. рис. 3.3).)
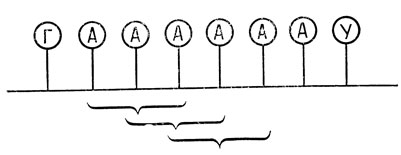
Другой загадкой, которая до недавнего времени оставалась неразрешенной, является проблема выбора отдельного "верного" триплета из данной последовательности оснований. Например, последовательность АЦГУ содержит два триплета - АЦГ и ЦГУ. Только один из них может быть "верным" триплетом, соответствующим определенной аминокислоте, которая должна войти в белок, запрограммированный данной мРНК. Если же начать синтез с выбора "неверного" триплета, то это приведет к непрерывной последовательности "неверных" триплетов, а следовательно, все аминокислоты будут "неверными", что будет означать "неверный" белок.
Однако таких ошибок в природе не происходит, и в конце 50-х годов Ф. Крик, Дж. Гриффит и Л. Оргел предложили остроумное объяснение этого явления. Принимая, что аминокислотный код основывается на последовательности триплетов (напоминающих трехбуквенные символы), они предположили, что код является неперекрывающимся. Это означает, что в гипотетическом регулярном полинуклеотиде УГАУГАУГА только один из трех триплетов (УГА ГАУ или АУГ) имеет какой-то "смысл". Два других являются "бессмысленными", так как не соответствуют никаким комплементарным триплетам на тРНК, и, следовательно, никакие тРНК не будут спариваться с этими триплетами.
Рассуждая далее, они считали, что если это верно, триплеты ААА, ЦЦЦ, ГГГ и УУУ не могли бы быть настоящими триплетами, потому что повторение любого из них может вызвать перекрывание, а следовательно, и неверное начало синтеза белка. Таким образом, число допустимых комбинаций трех оснований РНК уменьшается от 64 до 60. Далее они полагали, что из этих 60 комбинаций две трети должны быть бессмысленны, чтобы избежать перекрывания.
Такой перекрывающийся выбор триплета приводил бы к различным последовательностям аминокислот в белке
Тогда только одна треть из 60 будет "истинными" триплетами. Это число (двадцать) точно соответствует числу различных аминокислот, найденных в белках. Хотя это предположение прекрасно соответствовало тому, что было известно в то время, оно оказалось неверным. Последующая работа показала, что имеется более 20 значащих триплетов. Современные данные показывают, что выбор "верного" триплета происходит в результате преимущественного связывания тРНК на одном из концов мРНК, а не посреди ее цепи.
Как же определить, какой триплет послужит кодом для определенной аминокислоты? Наиболее прямым способом является приготовление синтетических полинуклеотидов с известной последовательностью оснований, использование этих молекул в качестве мРНК в белковом синтезе и затем определение последовательности аминокислот в белке.
Например, полинуклеотид, содержащий только один тип оснований, может быть получен из нуклеотидов (дифосфатов) и фермента, называемого полинуклеотидфосфорилазой, выделенного Очоа и Грюнберг-Манаго. Если основанием является урацил, синтетический полинуклеотид называется поли-У (УУУУУУУ...). В присутствии смеси молекул тРНК, ферментов и других компонентов клеток поли-У инициирует синтез полипептида, содержащего аминокислоты только одного вида - а именно полифенилаланин. Таким образом, ясно, что триплет УУУ является кодоном для фенилаланина.
Этот метод может быть распространен (и это было сделано Очоа и Ниренбергом) на кодоны со смешанными основаниями, Например, полимеризация урацила может быть инициирована динуклеотидом АУУУУУУ.... Этот полинуклеотид вызывает синтез полифенилаланина с одним остатком тирозина на конце. Следовательно, кодоном для аминокислоты тирозина должен быть триплет АУУ. В результате этой работы были составлены таблицы кодонов для всех двадцати аминокислот. Оказалось, что большинство аминокислот имеет более одного кодона.
Следовательно, согласно современным представлениям, каждый фермент синтезируется путем линейной последовательности реакций соединения аминокислот, начинающейся на одном конце мРНК и заканчивающейся на другом ее конце, где белковая цепь полностью освобождается. По мере образования очередной пептидной связи "отработанная" тРНК отходит от мРНК. Это позволяет свежим тРНК подносить аминокислоты и начинать синтез второй молекулы белка, не дожидаясь окончания синтеза первой молекулы (рис. 3.3).
![Рис. 3.3. Изображение последовательности белкового синтеза [5]. На этом рисунке АА обозначает аминокислоту; АТФ - аденозинтрифосфат; АМФ - аденозинмонофосфат; АА - АМФ - аденилат аминокислоты: тРНК - транспортную рибонуклеиновую кислоту; мРНК - информационную, или матричную, рибонуклеиновую кислоту, а, б и т. д. обозначают места связывания на рибосоме (тРНК), где происходит образование пептидной связи](pic/000098.jpg)
Рис. 3.3. Изображение последовательности белкового синтеза [5]. На этом рисунке АА обозначает аминокислоту; АТФ - аденозинтрифосфат; АМФ - аденозинмонофосфат; АА - АМФ - аденилат аминокислоты: тРНК - транспортную рибонуклеиновую кислоту; мРНК - информационную, или матричную, рибонуклеиновую кислоту, а, б и т. д. обозначают места связывания на рибосоме (тРНК), где происходит образование пептидной связи
|
ПОИСК:
|
При копировании ссылка обязательна:
http://biologylib.ru/ 'Библиотека по биологии'